|
I am a PhD student at the Robotics Institute at Carnegie Mellon University, where I am advised by Prof. Henny Admoni. I also collaborate with Prof. Andrea Bajcsy. During the summer of 2025, I was a Research Intern at Toyota Research Institute with the Human Interactive Driving Team. Previously, I was an MSR student at the Robotics Institute at Carnegie Mellon University, co-advised by Prof. Henny Admoni and Prof. David Held. Before that, I was a PreDoc Apprentice at TCS Research, working under Ms. Ramya Hebbalaguppe and Dr. Rahul Narain. I completed my undergraduate studies in computer science at IIIT Hyderabad, where I worked as a research assistant at CVIT under the guidance of Prof. Ravi Kiran Sarvadevabhatla. As a part of my Master's thesis at CMU, I developed a method for real-time driver's Situational Awareness (SA) estimation using their eye-gaze. Prior to this, I worked on the problem of estimating an object's importance for making a safe driving decision for the ego vehicle. At TCS, I worked on the problem of 3-D single view reconstruction. At CVIT, I worked on problems related to skeleton based action recognition and zero shot and generalised zero shot skeleton action recognition. I spent the summer of 2020 working as an Applied Scientist intern at Amazon India, where I worked on semantic text similarity using Bert based siamese networks. I have also worked under the supervision of Dr. Manish Gupta on Knowledge aware video question answering. Email / CV / Google Scholar / Twitter / Github |

|
|
My current research interests revolve around Human Robot Interaction, Shared Control for Robotics, Learning for Robotics and Assitive and Autonomous driving. I also have a keen interest in Computer Vision, 3D Computer Vision, Multimodal Learning and NLP. |
|
|

|
Pranay Gupta, Henny Admoni, Andrea Bajcsy 9th Annual Conference on Robot Learning (CoRL 2025) Paper / Project Page AbstractEnd-to-end visuomotor policies trained using behavior cloning have shown a remarkable ability to generate complex, multi-modal low-level robot behaviors. However, at deployment time, these policies still struggle to act reliably when faced with out-of-distribution (OOD) visuals induced by objects, backgrounds, or environment changes. Prior works in interactive imitation learning solicit corrective expert demonstrations under the OOD conditions---but this can be costly and inefficient. We observe that task success under OOD conditions does not always warrant novel robot behaviors. In-distribution (ID) behaviors can directly be transferred to OOD conditions that share functional similarities with ID conditions. For example, behaviors trained to interact with in-distribution (ID) pens can apply to interacting with a visually-OOD pencil. The key challenge lies in disambiguating which ID observations functionally correspond to the OOD observation for the task at hand. We propose that an expert can provide this OOD-to-ID functional correspondence. Thus, instead of collecting new demonstrations and re-training at every OOD encounter, our method: (1) detects the need for feedback by checking if current observations are OOD and the most similar training observations show divergent behaviors (2) solicits functional correspondence feedback to disambiguate between those behaviors, and (3) intervenes on the OOD observations with the functionally corresponding ID observations to perform deployment-time generalization. We validate our method across diverse real-world robotic manipulation tasks with a Franka Panda robotic manipulator. Our results show that test-time functional correspondences can improve the generalization of a vision-based diffusion policy to OOD objects and environment conditions with low feedback. |
|
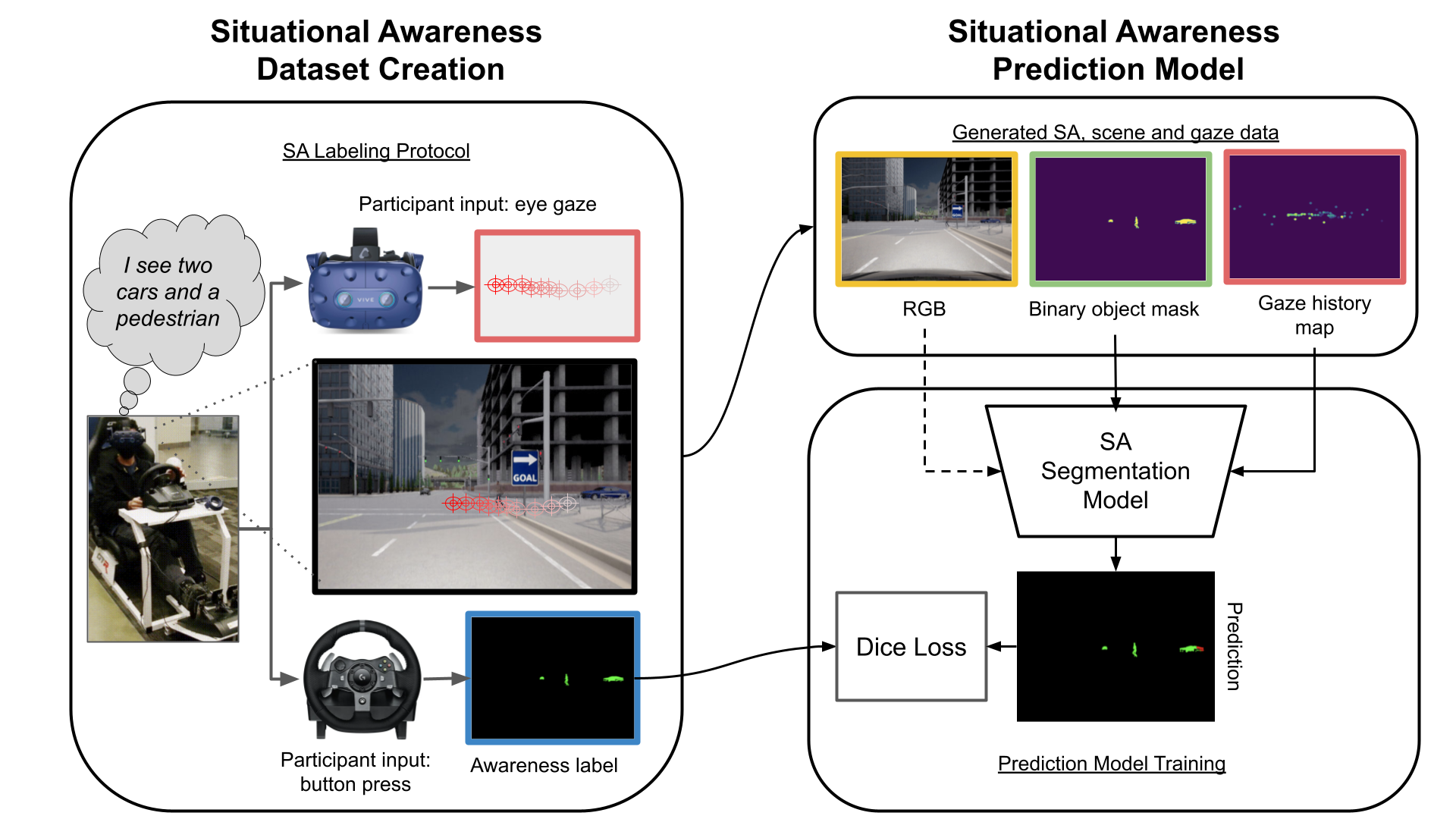
Abhijat Biswas, Pranay Gupta, Shreeya Khurana, David Held, Henny Admoni, 8th Annual Conference on Robot Learning (CoRL 2024) Paper AbstractIntelligent driving assistance can alert drivers to objects in their environment; however, such systems require a model of drivers' situational awareness (SA) (what aspects of the scene they are already aware of) to avoid unnecessary alerts. Moreover, collecting the data to train such an SA model is challenging: being an internal human cognitive state, driver SA is difficult to measure, and non-verbal signals such as eye gaze are some of the only outward manifestations of it. Traditional methods to obtain SA labels rely on probes that result in sparse, intermittent SA labels unsuitable for modeling a dense, temporally correlated process via machine learning. We propose a novel interactive labeling protocol that captures dense, continuous SA labels and use it to collect an object-level SA dataset in a VR driving simulator. Our dataset comprises 20 unique drivers' SA labels, driving data, and gaze (over 320 minutes of driving) which will be made public. Additionally, we train an SA model from this data, formulating the object-level driver SA prediction problem as a semantic segmentation problem. Our formulation allows all objects in a scene at a timestep to be processed simultaneously, leveraging global scene context and local gaze-object relationships together. Our experiments show that this formulation leads to improved performance over common sense baselines and prior art on the SA prediction task. |
|
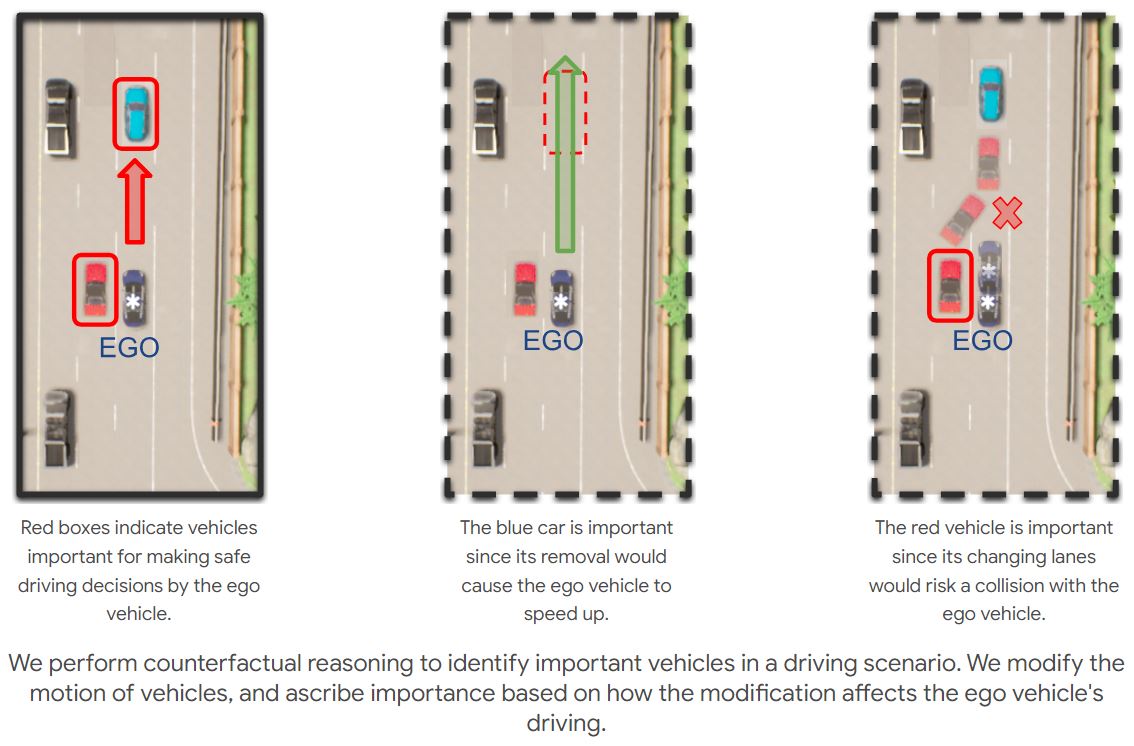
Pranay Gupta, Abhijat Biswas, Henny Admoni, David Held IEEE RA-L and ICRA 2025 Paper / Project Page / Code AbstractThe ability to identify important objects in a complex and dynamic driving environment is essential for autonomous driving agents to make safe and efficient driving decisions. It also helps assistive driving systems decide when to alert drivers. We tackle object importance estimation in a data-driven fashion and introduce HOIST - Human-annotated Object Importance in Simulated Traffic. HOIST contains driving scenarios with human-annotated importance labels for vehicles and pedestrians. We additionally propose a novel approach that relies on counterfactual reasoning to estimate an object's importance. We generate counterfactual scenarios by modifying the motion of objects and ascribe importance based on how the modifications affect the ego vehicle's driving. Our approach outperforms strong baselines for the task of object importance estimation on HOIST. We also perform ablation studies to justify our design choices and show the significance of the different components of our proposed approach. |

|
Pranay Gupta, Manish Gupta PAKDD, 2022 Paper AbstractIn this paper, we explore knowledge-based question answering in the context of news videos. To this end, we curate a new dataset with over 1M multiple-choice question-answer pairs. Using this dataset, we propose a novel approach, NEWSKVQA (Knowledge-Aware News Video Question Answering) which performs multi-modal inferencing over textual multiple-choice questions, videos, their transcripts and knowledge base |
|
Pranay Gupta, Anirudh Thatipelli, Aditya Aggarwal, Shubh Maheshwari, Neel Trivedi, Sourav Das, Sarvadevabhatla, Ravi Kiran IJCV, Special Issue on Human pose, Motion, Activities and Shape in 3D, 2021 Paper / Project Page / Code AbstractIn this paper, we study current and upcoming frontiers across the landscape of skeleton-based human action recognition. We introduce skeletics-152, a large scale into-the-wild skeleton action dataset. We extend out analysis to out of context actions by introducing Skelton-Mimetics dataset. Finally we introduce Metaphorics, a dataset with caption-style annotated YouTube videos of the popular social game Dumb Charades and interpretative dance performances. We benchmark state-of-the-art models on the NTU-120 dataset and provide multi-layered assessment of the results. |
|
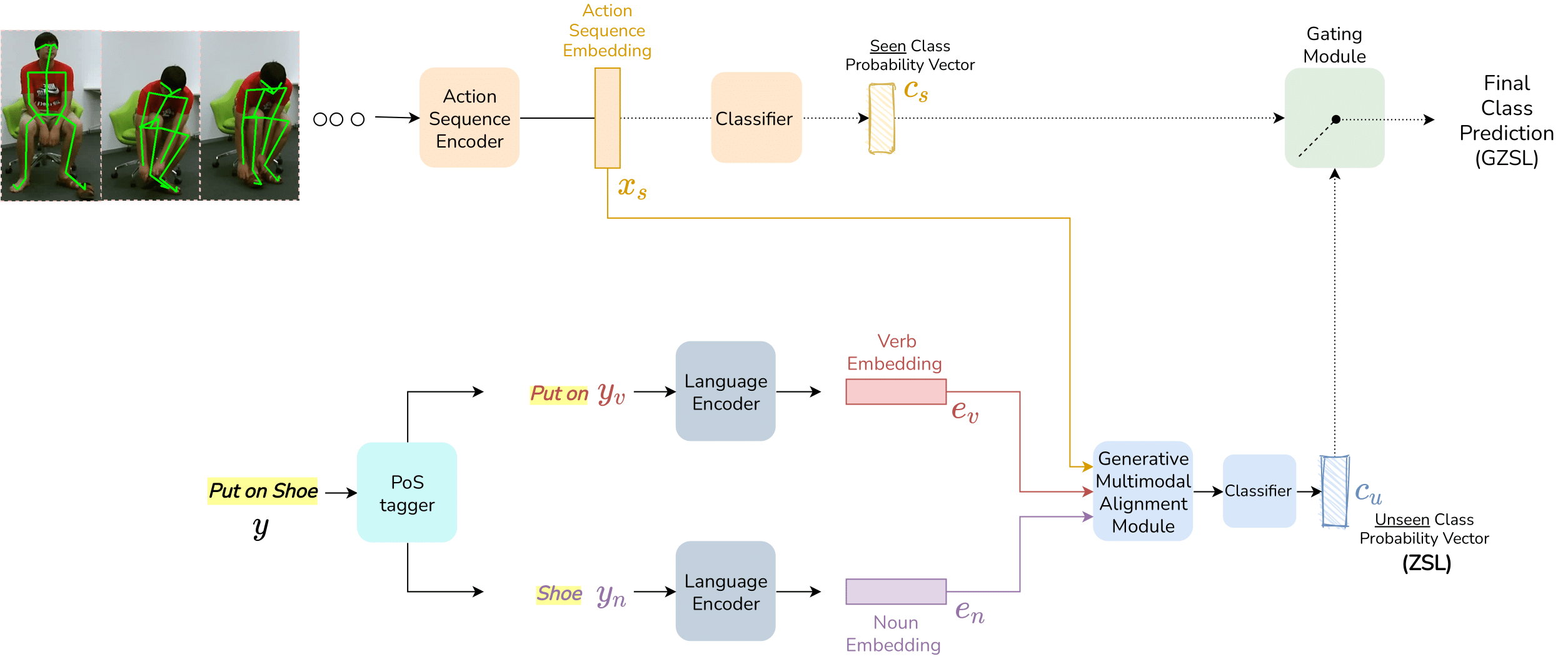
Pranay Gupta, Divyanshu Sharma, Sarvadevabhatla, Ravi Kiran ICIP, 2021 Paper / Project Page / Code AbstractIn this paper, we study the effect of learning Part of Speech aware generative embeddings for zero shot and generalised zero shot skelton action recognition. |
|
|

|
Abhijat Biswas*, Pranay Gupta*, David Held, Henny Admoni 7th International Workshop on Virtual, Augmented, and Mixed-Reality for Human-Robot Interactions (VAM-HRI) Paper AbstractCommonly used protocols for capturing the ground-truth situational awareness (SA) of drivers involve halting a simulation and querying the driver. SA data collected in this way is unsuitable for training models for predicting real-time SA since it is inherently intermittent and does not capture transitions of SA (e.g. from not aware to aware). We introduce an efficient VR based interactive protocol designed to capture a driver's ground-truth situational awareness (SA) in real time. Our protocol mitigates the aforementioned limitations of prior approaches, and allows capturing continuous object-level SA labels that are more suitable for downstream real-time SA prediction tasks. Our initial findings highlight its potential as a scalable solution for curating large scale driving datasets with ground-truth SA. |
|
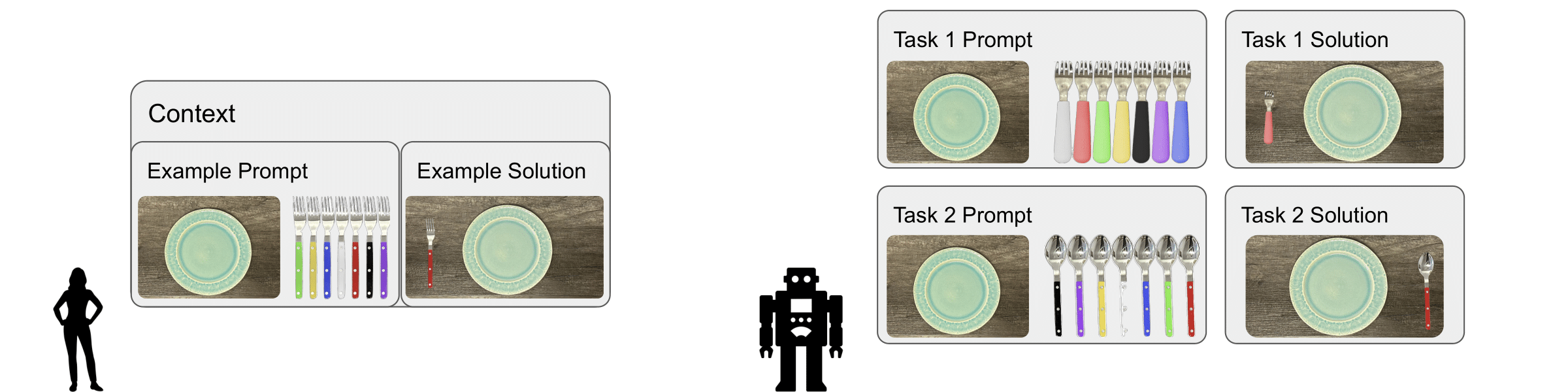
Benjamin A. Newman, Pranay Gupta, Yonatan Bisk, Kris Kitani, Henny Admoni, Chris Paxton HRI 24' Workshop on Human – Large Language Model Interaction Paper AbstractRobots should adhere to personal preferences when performing household tasks. Many household tasks can be posed as multi-object rearrangement tasks, but solutions to these problems often target a single, hand defined solution or are trained to match a solution drawn from a distribution of human demonstrated data. In this work, we consider using an internet-scale pre-trained vision-andlanguage foundation model as the backbone of a robot policy for producing personalized task plans to solve household multi-object rearrangement tasks. We present initial results on a one-step table setting task that shows a proof-of-concept for this method. |
|
|
| Reviewer: IEEE RA-L 2025, IEEE ICRA 2026, ACM HRI 2025, CoRL 2025 |
| Teaching Assistant: Human Robot Interaction (Fall 2024), Intro to Human Robot Interaction (Spring 2023), Computer Vision (Spring 2020) |
|
Design and source code from Jon Barron's website |